- When to use reinforcement fine-tuning
- Evals are the foundation
- How to get better results from RFT
- Other resources
Title: Reinforcement fine-tuning use cases - OpenAI API
URL Source: https://platform.openai.com/docs/guides/rft-use-cases
Markdown Content: Learn use cases and best practices for reinforcement fine-tuning.
Reinforcement fine-tuning (RFT) provides a way to improve your model’s performance at specific tasks. The task must be clear and have verifiable answers.
#When to use reinforcement fine-tuning
Agentic workflows are designed to make decisions that are both correct and verifiable. RFT can help by providing explicit rubrics and using code‑based or LLM‑based graders to measure functional success, factual accuracy, or policy compliance.
Across early users, three clear use cases have emerged:
- Turn instructions into working code: Convert open-ended prompts into structured code, configs, or templates that must pass deterministic tests.
- Pull facts into a clean format: Extract verifiable facts and summaries from messy, unstructured text and return JSON-structured or other schema-based outputs.
- Apply complex rules correctly: Make fine-grained label or policy decisions when the information provided is nuanced, large in quantity, hierarchical, or high-stakes.
Ready to use reinforcement fine-tuning? Skip to the guide →
#1. Turn instructions into working code
In this use case, models reason over hidden domain constraints to produce structured outputs like code, queries, or infrastructure templates. Outputs must satisfy multiple correctness conditions, and success is usually deterministically graded: the artifact either compiles, passes tests, or meets an explicit schema.
#Wiring verification IPs for semiconductor design
Use case
Company: ChipStack is building the next-generation of AI-powered tools for chip design and verification, aimed at significantly reducing the time and cost of developing and validating complex semiconductor chips.
Problem to solve: One task that’s challenging and time-consuming for humans is binding design interfaces to verification IPs (pre-created verification components that, when properly applied, can signifcantly enhance quality and coverage of verification). There are many verification IPs, and each can contain dozens to hundreds of signals that may be mapped. Someone must understand this domain well in order to apply the verification IP correctly.
Objective: To train OpenAI reasoning models to do this instead, ChipStack prepared a dataset consisting of less than 50 samples, then performed several RFT variations. For the final evaluation report, they ran this evaluation set three times against each model and variation—o1-mini base and fine-tuned, o3-mini base and fine-tuned—and averaged the results per-sample then overall.
Prompt
Below is a piece of example data provided.
1
2
3
4
[
{“name”: “BLOCK_SIZE”, “value”: “8”},
{“name”: “ADDR_WIDTH”, “value”: “4”}
]
Grader code
Below is a grader definition in Python of a string map, represented as a list of objects with
nameandvalueproperties.Conceptually, this is meant to model a type like
Dict[str, str].
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
"type": "python",
"name": "donors_caas",
"image_tag": "alpha",
"source": "from collections import Counter
def grade(sample: dict[str, str], item: dict[str, str]) -> float:
# multisets of (name, value) pairs
predicted = sample[\"output_json\"][\"predicted\"]
expected = item[\"reference_answer\"]
pred_counts = Counter((d[\"name\"], d[\"value\"]) for d in predicted)
exp_counts = Counter((d[\"name\"], d[\"value\"]) for d in expected)
true_pos = sum(min(pred_counts[p], exp_counts[p]) for p in pred_counts)
pred_total = sum(pred_counts.values())
exp_total = sum(exp_counts.values())
precision = true_pos / pred_total if pred_total else 0.0
recall = true_pos / exp_total if exp_total else 0.0
if precision + recall == 0.0:
return 0.0
return 2 * precision * recall / (precision + recall)"
}
Results
For both o1-mini and o3-mini, performance improved by ~12 percentage points. The fine-tuned variants got much better about recognizing when not to apply wiring. Many commercial verification IPs can contain hundreds of optional signals, most of which are not meant to be applied.
“Thanks to powerful base models and easy-to-use Reinforced Fine-Tuning APIs, we were able to significantly boost performance on our task with a small set of high-quality samples.”
—ChipStack, next-generation of AI-powered tools for chip design and verification
#Production-ready API snippets that compile and pass AST checks
Use case
Company: Runloop is a platform for AI-powered coding agents to be deployed into production and built with public and custom benchmarking capabilities to refine performance.
Problem to solve: Runloop wanted to improve model performance at using third-party APIs, such as the Stripe API, which can be large and complex without a human in the loop. If they could train a model to use the Stripe API, Runloop could turn economically impactful business cases into working code.
Objective: Their goal was teaching the model to master usage of the Stripe API, including writing complete code snippets for arbitrary user requests by either adapting information from existing integration guides, merging information from multiple guides, or inferring information not explicitly stated in the guides. They used RFT with two primary rewards:
- Reward the model for outputting the answer in a Markdown format that aligns with expectation of how a “dynamic” integration guide should look.
- Reward the model for producing “correct” code snippets by validating the outputted code via AST Grep. This allows them to confirm the model is making the correct Stripe SDK calls with the correct parameters and in some cases even in the correct order.
Grader code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
# Note this file gets uploaded to the OpenAI API as a grader
from ast_grep_py import SgRoot
from pydantic import BaseModel, Field # type: ignore
from typing import Any, List, Optional
import re
SUPPORTED_LANGUAGES = ['typescript', 'javascript', 'ts', 'js']
class CodeBlock(BaseModel):
language: str = Field(
description="Programming language of the code block (e.g., 'python', 'javascript')",
examples=["python", "javascript", "typescript"]
)
path: str = Field(
description="Target file path where the code should be written",
examples=["main.py", "src/app.js", "index.html"]
)
code: str = Field(
description="Actual code content extracted from the code block"
)
class ASTGrepPattern(BaseModel):
file_path_mask: str = Field(..., description="The file path pattern to match against")
pattern: str = Field(..., description="The main AST grep pattern to search for")
additional_greps: Optional[List[str]] = Field(
default=None,
description="Additional patterns that must also be present in the matched code"
)
def extract_code_blocks(llm_output: str) -> List[CodeBlock]:
# Regular expression to match code blocks with optional language and path
try:
pattern = r"```(\w+\s+)?([\w./-]+)?\n([\s\S]*?)\n```"
matches = list(re.finditer(pattern, llm_output, re.DOTALL))
print(f"Found {len(matches)} code blocks in the LLM output")
# Check if any code blocks were found
if not matches:
raise Exception("No code blocks found in the LLM response")
code_blocks: list[CodeBlock] = []
for match in matches:
language = match.group(1) or ""
path = match.group(2) or ""
code = match.group(3)
# Clean the path and language
path = path.strip()
language = language.strip()
# If path is relative (doesn't start with /), prefix with /home/user/testbed/
if path and not path.startswith("/"):
original_path = path
path = f"/home/user/testbed/{path}"
print(
f"Converting relative path '{original_path}' to absolute path '{path}'"
)
code_blocks.append(
CodeBlock(language=language, path=path, code=code.strip())
)
# Check for missing language or path in code blocks
missing_language = [
i for i, block in enumerate(code_blocks) if not block.language
]
missing_path = [i for i, block in enumerate(code_blocks) if not block.path]
if missing_language:
print(
f"WARNING: Code blocks at positions {missing_language} are missing language identifiers"
)
raise Exception(
f"Code blocks at positions {missing_language} are missing language identifiers"
)
if missing_path:
print(
f"WARNING: Code blocks at positions {missing_path} are missing file paths"
)
raise Exception(
f"Code blocks at positions {missing_path} are missing file paths"
)
paths = [block.path for block in code_blocks if block.path]
print(
f"Successfully extracted {len(code_blocks)} code blocks with paths: {', '.join(paths)}"
)
except Exception as e:
print(f"Error extracting code blocks: {str(e)}")
raise
return code_blocks
def calculate_ast_grep_score(code_blocks: List[CodeBlock], ast_greps: Any) -> float:
# Convert ast_greps to list if it's a dict
if isinstance(ast_greps, dict):
ast_greps = [ast_greps]
# Parse each grep pattern into the Pydantic model
parsed_patterns: List[ASTGrepPattern] = []
for grep in ast_greps:
try:
pattern = ASTGrepPattern(**grep)
parsed_patterns.append(pattern)
except Exception as e:
print(f"Error parsing AST grep pattern: {e}")
return 0.0
if not parsed_patterns:
return 0.0
total_score = 0.0
pattern_count = len(parsed_patterns)
# Filter code blocks to only include TypeScript and JavaScript files
supported_blocks = [
block for block in code_blocks
if block.language.lower() in SUPPORTED_LANGUAGES
]
if not supported_blocks:
print("No TypeScript or JavaScript code blocks found to analyze")
return 0.0
for pattern in parsed_patterns:
# Find matching code blocks based on path prefix
matching_blocks = [
block for block in supported_blocks
if block.path.startswith(pattern.file_path_mask)
]
if not matching_blocks:
print(f"No matching code blocks found for path prefix: {pattern.file_path_mask}")
continue
pattern_found = False
for block in matching_blocks:
try:
# Create AST root for the code block
root = SgRoot(block.code, block.language)
node = root.root()
# Check main pattern
matches = node.find(pattern=pattern.pattern)
if not matches:
continue
# If we have additional greps, check them too
if pattern.additional_greps:
all_additional_found = True
for additional_grep in pattern.additional_greps:
if additional_grep not in block.code:
all_additional_found = False
break
if not all_additional_found:
continue
# If we get here, we found a match with all required patterns
pattern_found = True
break
except Exception as e:
print(f"Error processing code block {block.path}: {e}")
continue
if pattern_found:
total_score += 1.0
# Return average score across all patterns
return total_score / pattern_count if pattern_count > 0 else 0.0
def grade_format(output_text: str) -> float:
# Find <plan> and </plan> tags
plan_start = output_text.find('<plan>')
plan_end = output_text.find('</plan>')
# Find <code> and </code> tags
code_start = output_text.find('<code>')
code_end = output_text.find('</code>')
reward = 0.0
if plan_start == -1 or plan_end == -1 or code_start == -1 or code_end == -1:
print(f'missing plan or code tags. format reward: {reward}')
return reward
reward += 0.1 # total: 0.1
if not (plan_start < plan_end < code_start < code_end):
print(f'tags present but not in the correct order. format reward: {reward}')
return reward
reward += 0.1 # total: 0.2
# Check if there are any stray tags
plan_tags = re.findall(r'</?plan>', output_text)
code_tags = re.findall(r'</?code>', output_text)
if len(plan_tags) != 2 or len(code_tags) != 2:
print(f'found stray plan or code tags. format reward: {reward}')
return reward
reward += 0.2 # total: 0.4
# Extract content after </code> tag
after_tags = output_text[code_end + len('</code>'):].strip()
if after_tags:
print(f'found text after code tags. format reward: {reward}')
return reward
reward += 0.2 # total: 0.6
# Extract content inside <plan> tags
plan_content = output_text[plan_start + len('<plan>'):plan_end].strip()
if not plan_content:
print(f'no plan content found. format reward: {reward}')
return reward
reward += 0.1 # total: 0.7
# Extract content inside <code> tags
code_content = output_text[code_start + len('<code>'):code_end].strip()
if not code_content:
print(f'no code content found. format reward: {reward}')
return reward
reward += 0.1 # total: 0.8
# Extract content between </plan> and <code> tags
between_tags = output_text[plan_end + len('</plan>'):code_start].strip()
if between_tags:
print(f'found text between plan and code tags. format reward: {reward}')
return reward
reward += 0.2 # total: 1.0
if reward == 1.0:
print(f'global format reward: {reward}')
return reward
def grade(sample: Any, item: Any) -> float:
try:
output_text = sample["output_text"]
format_reward = grade_format(output_text)
if format_reward < 1.0:
return format_reward
# Extract code content for grading
code_start = output_text.find('<code>')
code_end = output_text.find('</code>')
code_to_grade: str = output_text[code_start + len('<code>'):code_end].strip()
code_blocks: List[CodeBlock] = []
try:
code_blocks = extract_code_blocks(code_to_grade)
except Exception as e:
print(f'error extracting code blocks: {e}')
return 0.5
ast_greps = item["reference_answer"]["ast_greps"]
ast_grep_score = calculate_ast_grep_score(code_blocks, ast_greps)
return (format_reward + ast_grep_score) / 2.0
except Exception as e:
print(f"Error during grading: {str(e)}")
return 0.0
Results
Looking at the total reward (format and AST Grep) together, Runloop has seen improvements of on average 12% of the RFT model compared to the base o3-mini model on the benchmark.
They implement two types of tests, one providing explicit content from the integration guides (assessing reasoning and instruction following) and one without (assessing knowledge recall). Both variants saw improvement of over 8%.
“OpenAIs RFT platform gives us access to the best generalized reasoning models in the world, with the toolset to supercharge that reasoning on problem domains important to our business.”
#Correct handling of conflicts and dupes in a schedule manager
Use case
Company: Milo helps busy parents manage chaotic family schedules by converting messy inputs—like text convos with to-dos, school newsletter PDFs, weekly reminders, sports schedule emails—into reliable calendar and list actions.
Problem to solve: Base GPT-4o prompting and SFT fell short of trust thresholds.
Objective: Milo used RFT to properly create coding tasks like event vs. list classification, recurrence rule generation, accurate updates and deletes, conflict detection, and strict output formatting. They defined a grader that checked whether generated item objects were complete, categorized correctly, and were a duplicate or had a calendar conflict.
Results
Results showed performance improvements across the board, with average correctness scores increasing from 0.86 to 0.91, while the most challenging scenarios improved from 0.46 to 0.71 (where a perfect score=1).
“Accuracy isn’t just a metric—it’s peace of mind for busy parents. These are still early days but with such important improvements in base performance, we’re able to push more aggressively into complex reasoning needs.”
“Navigating and supporting family dynamics involves understanding nuanced implications of the data. Take conflicts—knowing soccer for Ethan conflicts with Ella’s recital because Dad has to drive both kids goes deeper than simple overlapping times.”
—Milo, AI scheduling tool for families
#2. Pull facts into a clean format
These tasks typically involve subtle distinctions that demand clear classification guidelines. Successful framing requires explicit and hierarchical labeling schemes defined through consensus by domain experts. Without consistent agreement, grading signals become noisy, weakening RFT effectiveness.
#Assigning ICD-10 medical codes
Use case
Company: Ambience is an AI platform that eliminates administrative burden for clinicians and ensures accurate, compliant documentation across 100+ specialties, helping physicians focus on patient care while increasing documentation quality and reducing compliance risk for health systems.
Problem to solve: ICD-10 coding is one of the most intricate administrative tasks in medicine. After every patient encounter, clinicians must map each diagnosis to one of ~70,000 codes—navigating payor-specific rules on specificity, site-of-care, and mutually exclusive pairings. Errors can trigger audits and fines that stretch into nine figures.
Objective: Using reinforcement fine-tuning on OpenAI frontier models, Ambience wanted to train a reasoning system that listens to the visit audio, pulls in relevant EHR context, and recommends ICD-10 codes with accuracy exceeding expert clinicians.
Results
Ambience achieved model improvements that can lead human experts.
On a gold-panel test set spanning hundreds of encounters, reinforcement fine-tuning moved the model from trailing humans to leading them by 12 points—eliminating roughly one quarter of the coding errors trained physicians make:
- o3-mini (base): 0.39 (-6 pts)
- Physician baseline: 0.45
- RFT-tuned o3-mini: 0.57 (+12 pts)
The result is a real-time, point-of-care coding support that can raise reimbursement integrity while reducing compliance risk.
“Accurate ICD-10 selection is mission-critical for compliant documentation. RFT unlocked a new level of coding precision we hadn’t seen from any foundation model and set a new bar for automated coding.”
#Extracting excerpts to support legal claims
Use case
Company: Harvey is building AI that legal teams trust—and that trust hinges on retrieving precisely the right evidence from a sprawling corpora of contracts, statutes, and case law. Legal professionals aren’t satisfied with models that merely generate plausible-sounding summaries or paraphrased answers. They demand verifiable citations—passages that can be traced directly back to source documents.
Problem to solve: Harvey’s clients use its models to triage litigation risk, construct legal arguments, and support due diligence for legal professionals—all tasks where a single missed or misquoted sentence can flip an outcome. Models must be able to parse long, dense legal documents and extract only the portions that matter. In practice, these inputs are often messy and inconsistent: some claims are vague, while others hinge on rare legal doctrines buried deep in boilerplate.
Objective: The task’s requirements are to interpret nuanced legal claims, navigate long-form documents, and select on-point support with verbatim excerpts.
Prompt
1
2
3
4
5
6
## Instructions
You will be provided with a question and a text excerpt. Identify any passages in the text that are directly relevant to answering the question.
- If there are no relevant passages, return an empty list.
- Passages must be copied **exactly** from the text. Do not paraphrase or summarize.
## Excerpt
"""{text_excerpt}"""
Grader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
from rapidfuzz import fuzz
# Similarity ratio helper
def fuzz_ratio(a: str, b: str) -> float:
"""Return a normalized similarity ratio using RapidFuzz.
"""
if len(a) == 0 and len(b) == 0:
return 1.0
return fuzz.ratio(a, b) / 100.0
# Main grading entrypoint (must be named `grade`)
def grade(sample: dict, item: dict) -> float:
"""Compute an F1‑style score for citation extraction answers using RapidFuzz.
"""
model_passages = (sample.get('output_json') or {}).get('passages', [])
ref_passages = (item.get('reference_answer') or {}).get('passages', [])
# If there are no reference passages, return 0.
if not ref_passages:
return 0.0
# Recall: average best match for each reference passage.
recall_scores = []
for ref in ref_passages:
best = 0.0
for out in model_passages:
score = fuzz_ratio(ref, out)
if score > best:
best = score
recall_scores.append(best)
recall = sum(recall_scores) / len(recall_scores)
# Precision: average best match for each model passage.
if not model_passages:
precision = 0.0
else:
precision_scores = []
for out in model_passages:
best = 0.0
for ref in ref_passages:
score = fuzz_ratio(ref, out)
if score > best:
best = score
precision_scores.append(best)
precision = sum(precision_scores) / len(precision_scores)
if precision + recall == 0:
return 0.0
return 2 * precision * recall / (precision + recall)
Results
After reinforcement fine-tuning, Harvey saw a 20% increase in the F1 score:
- Baseline F1: 0.563
- Post-RFT F1 - 0.6765
Using RFT, Harvey significantly improved legal fact-extraction performance, surpassing GPT-4o efficiency and accuracy. Early trials showed RFT winning or tying in 93% of comparisons against GPT-4o.
“The RFT model demonstrated comparable or superior performance to GPT-4o, but with significantly faster inference, proving particularly beneficial for real-world legal use cases.
—Harvey, AI for legal teams
#3. Apply complex rules correctly
This use case involves pulling verifiable facts or entities from unstructured inputs into clearly defined schemas (e.g., JSON objects, condition codes, medical codes, legal citations, or financial metrics).
Successful extraction tasks typically benefit from precise, continuous grading methodologies—like span-level F1 scores, fuzzy text-matching metrics, or numeric accuracy checks—to evaluate how accurately the extracted information aligns with ground truth. Define explicit success criteria and detailed rubrics. Then, the model can achieve reliable, repeatable improvements.
#Expert-level reasoning in tax analysis
Use case
Company: Accordance is building a platform for tax, audit, and CPA teams.
Problem to solve: Taxation is a highly complex domain, requiring deep reasoning across nuanced fact patterns and intricate regulations. It’s also a field that continues changing.
Objective: Accordance wanted a high-trust system for sophisticated tax scenarios while maintaining accuracy. Unlike traditional hardcoded software, it’s important that their data extraction tool adapts as the tax landscape evolves.
Grader code
1
2
3
4
5
6
7
8
9
10
11
12
[+0.05] For correctly identifying Alex (33.33%), Barbara (33.33% → 20%), Chris (33.33%), and Dana (13.33%) ownership percentages
[+0.1] For correctly calculating Barbara's annual allocation as 26.67% and Dana's as 6.67% without closing of books
[+0.15] For properly allocating Alex ($300,000), Barbara ($240,030), Chris ($300,000), and Dana ($60,030) ordinary income
[+0.1] For calculating Alex's ending stock basis as $248,333 and debt basis as $75,000
[+0.05] For calculating Barbara's remaining basis after sale as $264,421
[+0.1] For calculating AAA before distributions as $1,215,000 and ending AAA as $315,000
[+0.1] For identifying all distributions as tax-free return of capital under AAA
[+0.1] For calculating Barbara's capital gain on stock sale as $223,720 ($400,000 - $176,280)
[+0.1] For explaining that closing of books would allocate based on actual half-year results
[+0.05] For identifying the ordering rules: AAA first, then E&P ($120,000), then remaining basis
[+0.05] For noting distributions exceeding $1,215,000 would be dividends up to $120,000 E&P
[+0.05] For correctly accounting for separately stated items in basis calculations (e.g., $50,000 Section 1231 gain)
Results
By collaborating with OpenAI and their in-house tax experts, Accordance achieved:
- Almost 40% improvement in tax analysis tasks over base models
- Superior performance compared to all other leading models on benchmarks like TaxBench
- The RFT-trained models demonstrated an ability to handle advanced tax scenarios with high accuracy—when evaluated by tax professionals, Accordance’s fine-tuned models showed expert-level reasoning, with the potential to save thousands of hours of manual work
“We’ve achieved a 38.89% improvement in our tax analysis tasks over base models and significantly outperformed all other leading models on key tax benchmarks (including TaxBench). The RFT-trained models’ abilities to handle sophisticated tax scenarios while maintaining accuracy demonstrates the readiness of reinforcement fine-tuning—and AI more broadly—for professional applications. Most importantly, RFT provides a foundation for continuous adaptation as the tax landscape evolves, ensuring sustained value and relevance. When evaluated by tax experts, our fine-tuned models demonstrated expert-level reasoning capabilities that will save thousands of professional hours—this isn’t just an incremental improvement, it’s a paradigm shift in how tax work can be done.”
—Accordance, AI tax accounting company
#Enforcement of nuanced content moderation policies
Use case
Company: SafetyKit is a risk and compliance platform that helps organizations make decisions across complex content moderation workflows.
Porblem to solve: These systems must handle large volumes of content and apply intricate policy logic that requires multistep reasoning. Because of the volume of data and subtle distinctions in labelling, these types of tasks can be difficult for general purpose models.
Objective: SafetyKit aimed to replace multiple nodes in their most complex workflows with a single reasoning agent using a reinforcement fine-tuned model. The goal is to reduce SafetyKit’s time-to-market for novel policy enforcements even in challenging, nuanced domains.
Results
SafetyKit is using their o3-mini RFT model to support advanced content moderation capabilities, ensuring user safety for one of the largest AI chatbot companies in the world. They have successfully improved F1-score from 86% to 90%, soon to replace dozens of 4o calls within their production pipeline.
“SafetyKit’s RFT-enabled moderation achieved substantial improvements in nuanced content moderation tasks, crucial for safeguarding users in dynamic, real-world scenarios.”
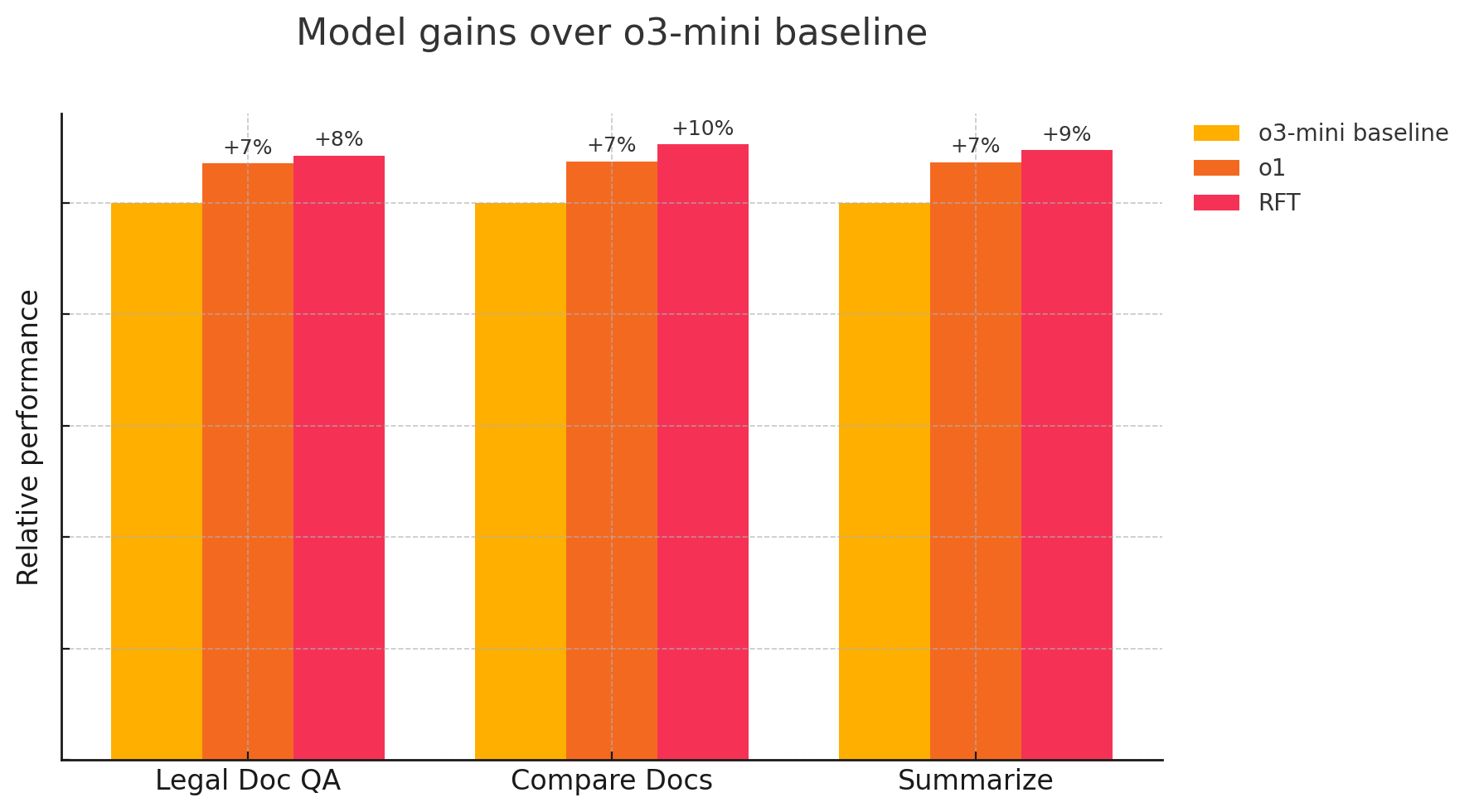
#Legal document reviews, comparisons, and summaries
Use case
Company: Thomson Reuters is an AI and technology company empowering professionals with trusted content and workflow automation.
Problem to solve: Legal professionals must read through large amounts of content before making any decisions. Thomson Reuter’s CoCounsel product is designed to help these experts move faster by providing an AI assistant with content and industry knowledge. The models that power this tool must understand complex legal rules.
Objective: Thomson Reuters aimed to create a reinforcement fine-tuned model excelling in legal AI skills. They conducted preliminary evaluations of RFT to see if they could achieve model performance improvements, using specialized datasets from three highly-used CoCounsel Legal AI skills for legal professionals:
- Review documents: Generates detailed answers to questions asked against contracts, transcripts, and other legal documents
- Compare documents: Highlights substantive differences between two or more different contracts or documents
- Summarize: Summarizes the most important information within one or more documents to enable rapid legal review
Results
“LLM as a judge has been helpful in demonstrating the possibility of improving upon the reasoning models - in preliminary evaluations, the RFT model consistently performed better than the baseline o3-mini and o1 model”
—Thomson Reuters, AI and technology company
#Evals are the foundation
Before implementing RFT, we strongly recommended creating and running an eval for the task you intend to fine-tune on. If the model you intend to fine-tune scores at either the absolute minimum or absolute maximum possible score, then RFT won’t be useful to you.
RFT works by reinforcing better answers to provided prompts. If we can’t distinguish the quality of different answers (i.e., if they all receive the minimum or maximum possible score), then there’s no training signal to learn from. However, if your eval scores somewhere in the range between the minimum and maximum possible scores, there’s enough data to work with.
An effective eval reveals opportunities where human experts consistently agree but current frontier models struggle, presenting a valuable gap for RFT to close. Get started with evals.
#How to get better results from RFT
To see improvements in your fine-tuned model, there are two main places to revisit and refine: making sure your task is well defined, and making your grading scheme more robust.
#Reframe or clarify your task
Good tasks give the model a fair chance to learn and let you quantify improvements.
- Start with a task the model can already solve occasionally. RFT works by sampling many answers, keeping what looks best, and nudging the model toward those answers. If the model never gets the answer correct today, it cannot improve.
- Make sure each answer can be graded. A grader must read an answer and produce a score without a person in the loop. We support multiple grader types, including custom Python graders and LLM judges. If you can’t write code to judge the answer with an available grader, RFT is not the right tool.
- Remove doubt about the “right” answer. If two careful people often disagree on the solution, the task is too fuzzy. Rewrite the prompt, add context, or split the task into clearer parts until domain experts agree.
- Limit lucky guesses. If the task is multiple choice with one obvious best pick, the model can win by chance. Add more classes, ask for short open‑ended text, or tweak the format so guessing is costly.
#Strengthen your grader
Clear, robust grading schemes are essential for RFT.
- Produce a smooth score, not a pass/fail stamp. A score that shifts gradually as answers improve provides a better training signal.
- Guard against reward hacking. This happens when the model finds a shortcut that earns high scores without real skill.
- Avoid skewed data. Datasets in which one label shows up most of the time invite the model to guess that label. Balance the set or up‑weight rare cases so the model must think.
- Use an LLM judge when code falls short. For rich, open‑ended answers, have a separate OpenAI model grade your fine-tuned model’s answers. Make sure you:
- Evaluate the judge: Run multiple candidate responses and correct answers through your LLM judge to ensure the grade returned is stable and aligned with preference.
- Provide few-shot examples. Include great, fair, and poor answers in the prompt to improve the grader’s effectiveness.
Learn more about grader types.
#Other resources
For more inspiration, visit the OpenAI Cookbook, which contains example code and links to third-party resources, or learn more about our models and reasoning capabilities: